Building TailorSwan: An AI Resume Tailoring Platform
Most job seekers send the same resume to every company. Most of those resumes get filtered out before a human ever reads them. I built TailorSwan to fix that — not by writing resumes for people, but by helping them present what they've actually done in the language each specific job is looking for.

The Problem Worth Solving
ATS (Applicant Tracking Systems) are keyword matchers at their core. A resume that accurately represents a strong candidate can score near zero simply because it doesn't mirror the vocabulary of the job description. The irony is that the candidate isn't underqualified — their resume just isn't translated for that role yet.
Manual tailoring works, but it's slow, error-prone, and easy to get wrong. You start inventing bullet points. You pad things. You lose track of which version you sent where. I wanted a tool that would do the tailoring faithfully — and critically, only from what's actually on the resume.
What TailorSwan Does
TailorSwan is a full-stack web application where users maintain one canonical resume and create separate job sessions — one per application. Each session holds the job description, the tailored version of the resume, a cover letter, and research on who to contact at the company.
The core workflow is:
Upload your resume — PDF, DOCX, or plain text. The backend parses it into a structured document with typed sections (experience, skills, projects, education, etc.)
Add a job — paste the JD or drop in a URL. The app fetches and extracts the job details automatically, including normalizing LinkedIn job URLs.
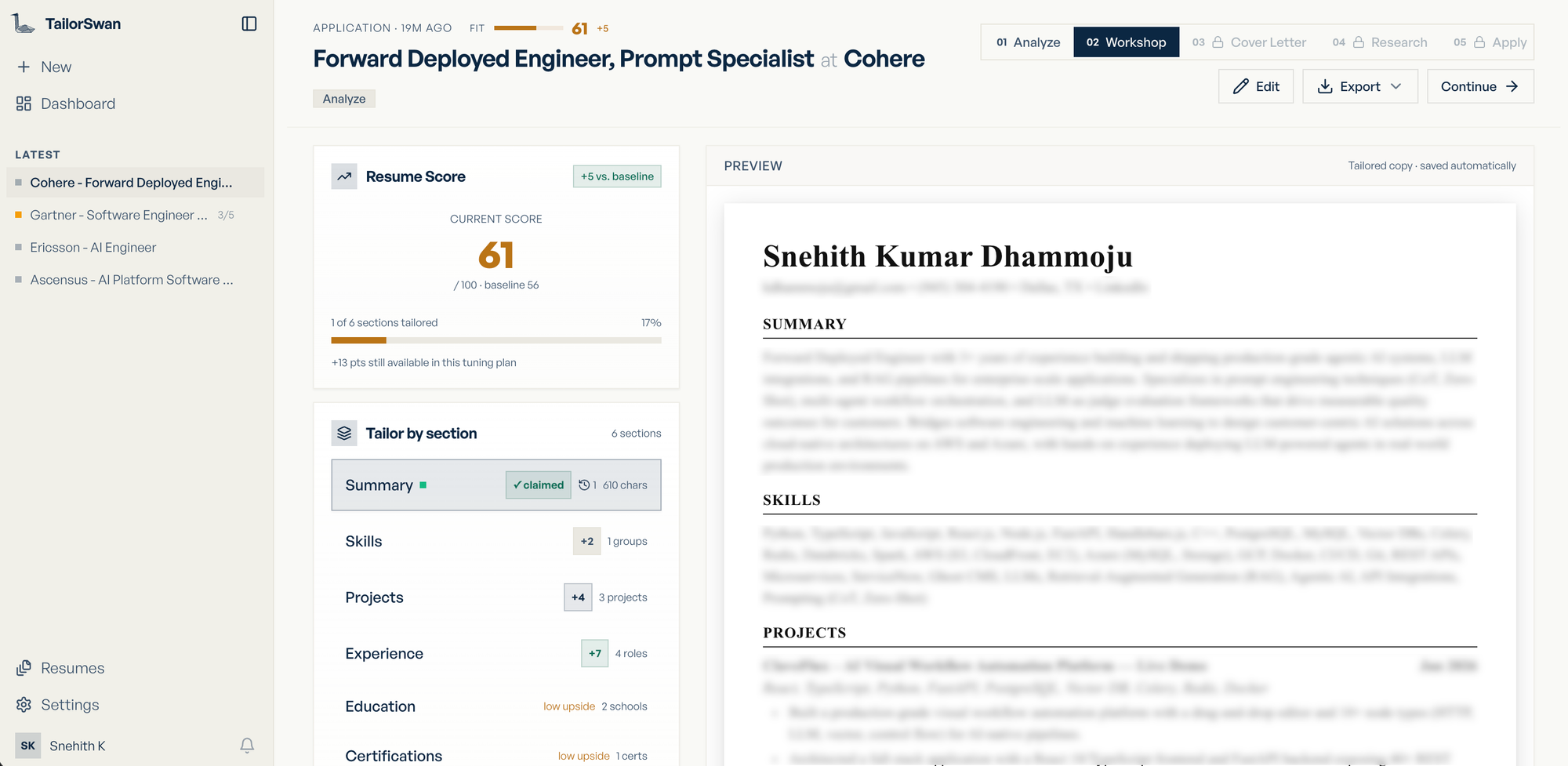
Analyze fit — the system scores the resume against the JD using an ATS keyword scan score and a deeper alignment score based on how well your actual experience covers the role's responsibilities. The two combine into an overall score with a verdict: apply, tailor first, or skip.
Tailor in the Workshop — section by section, request an AI rewrite targeted to the JD. Review a word-level diff showing exactly what changed. Approve, re-roll, or restore any previous version from history.
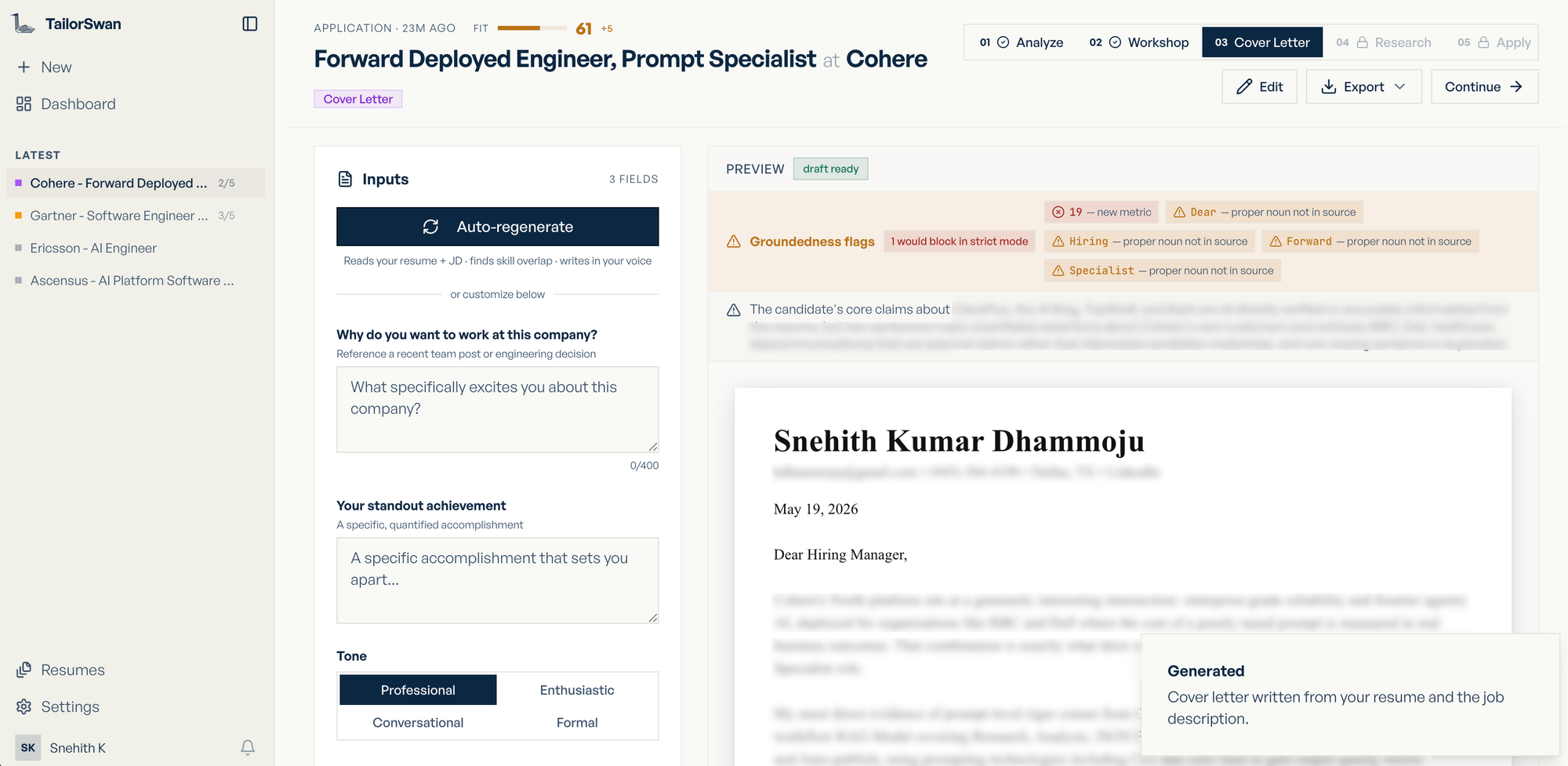
Generate a cover letter — personalized to the role and company, in your tone.
Research contacts — the platform surfaces people at the target company through enriched contact data pipelines.
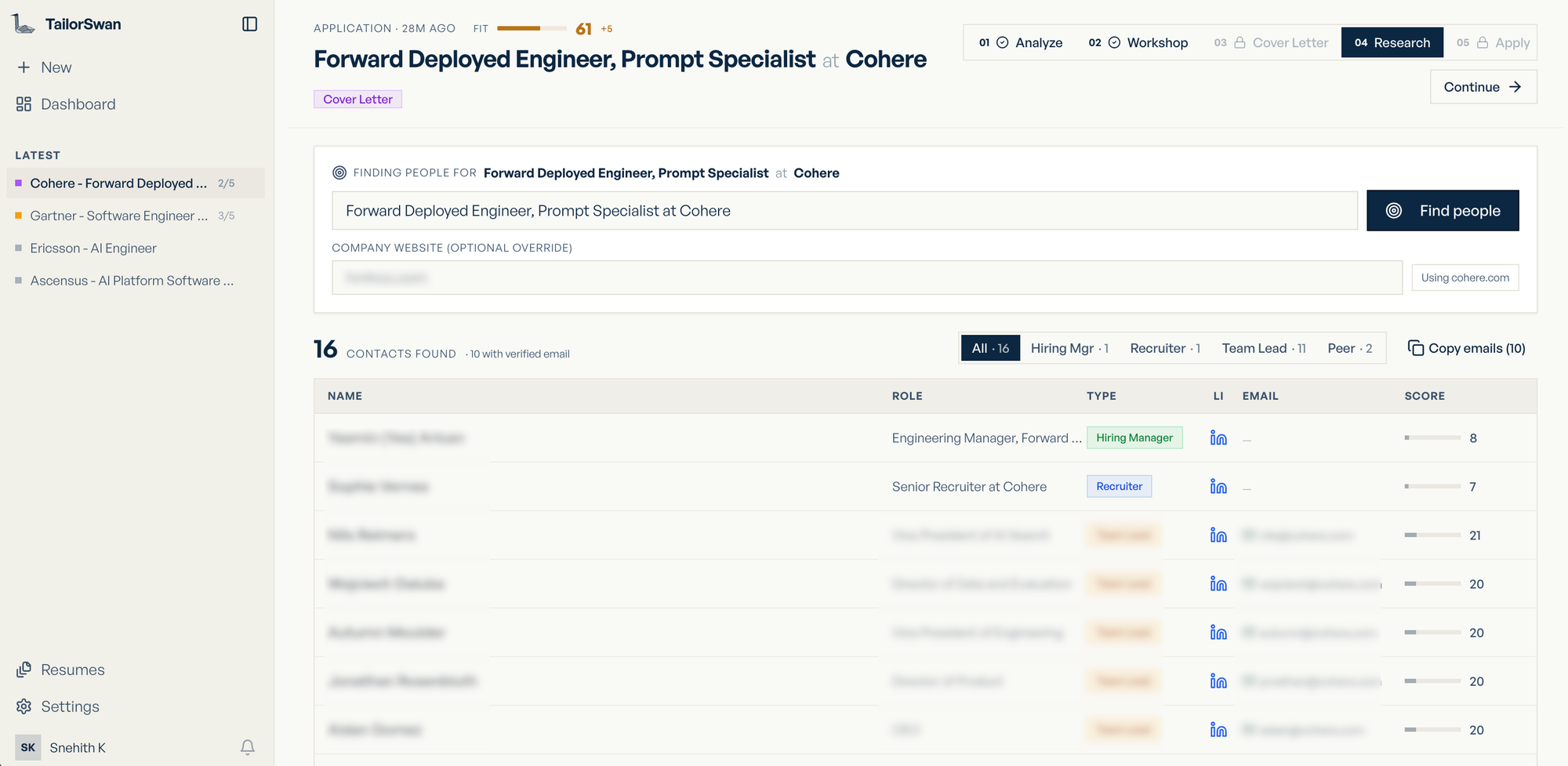
Apply — Each application keeps the original job URL on record, so when you're ready, you apply directly from the same session and update the status in one place — no hunting for the listing again.
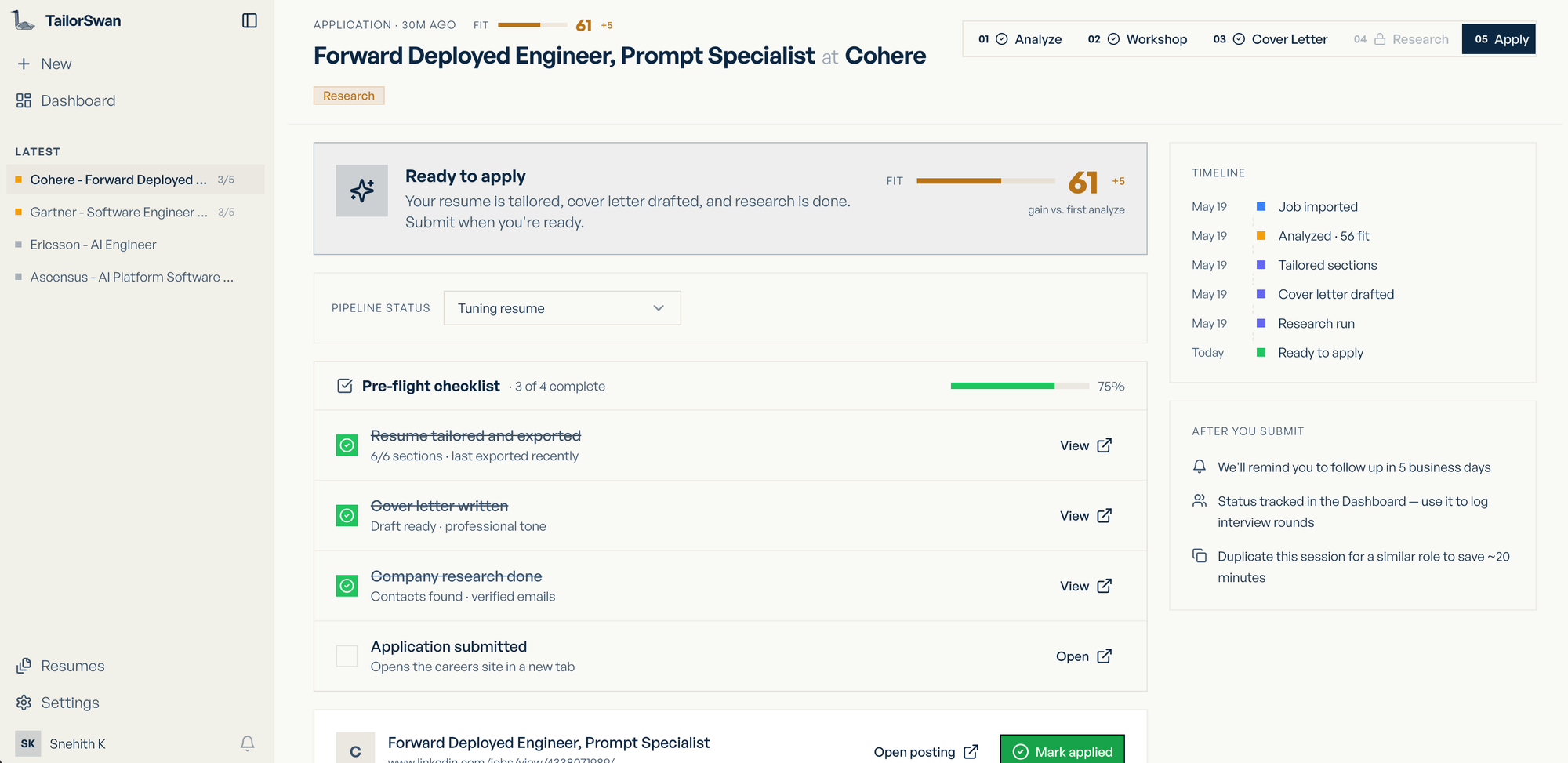
The Dashboard
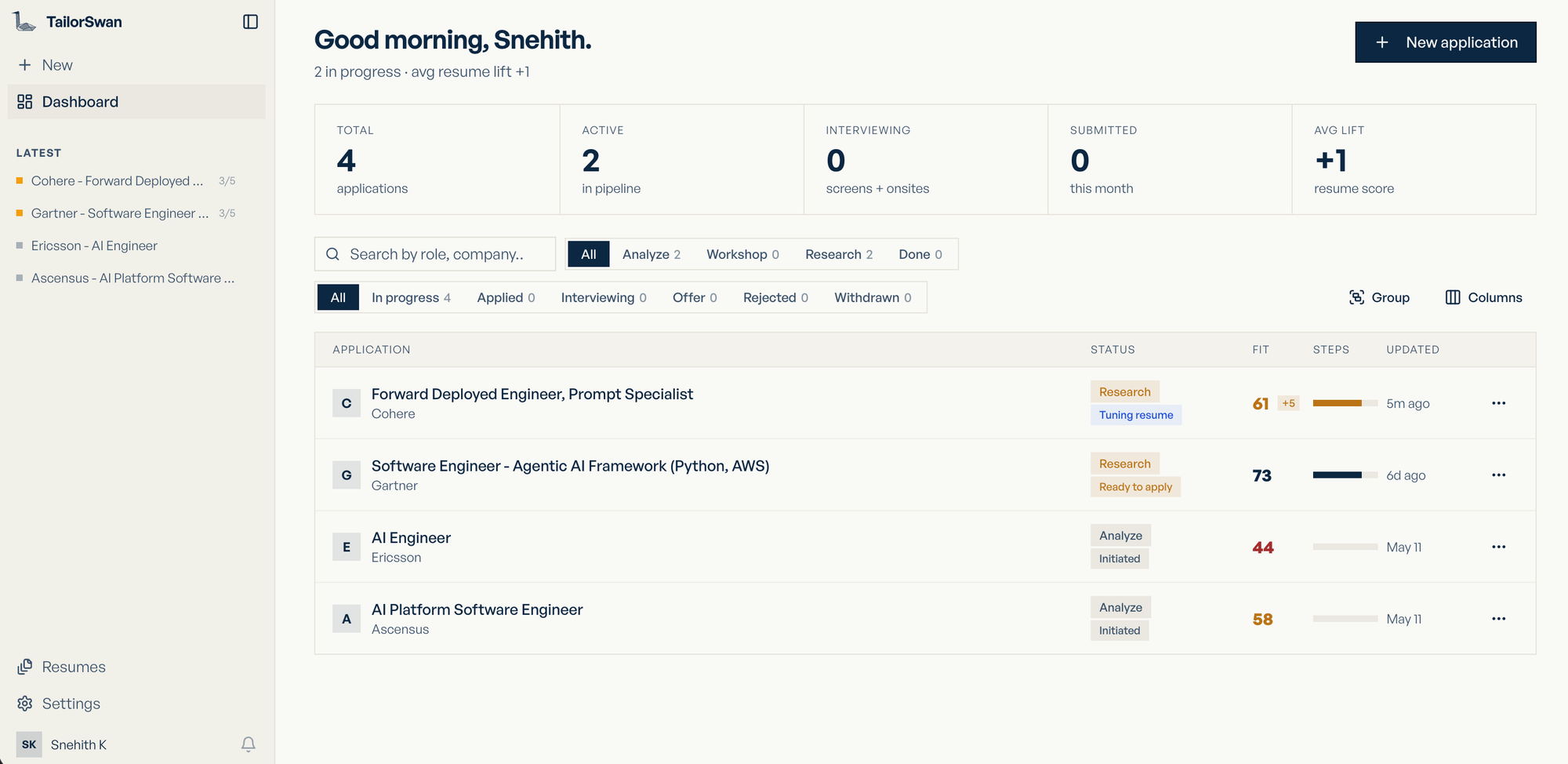
The command center for your entire job search. At a glance it shows total applications, how many are active in the pipeline, and an average resume lift score — a single number that tracks how much your tailoring has moved the needle across all sessions.
The Engineering Core
The backend is a Node.js/TypeScript API using Express, PostgreSQL, and two AI providers working in a coordinated pipeline: Anthropic Claude handles structured extraction and tailoring, while Perplexity Sonar handles live web search for job fetching and company research.
The most interesting engineering problem was making the AI honest. It's easy to get a language model to write a great-sounding bullet point — the hard part is making sure it's grounded in what the candidate actually did.
TailorSwan enforces this through a three-layer groundedness system:
- Layer A builds an allow-list of facts, names, tools, and metrics from the source resume before any AI call is made
- Layer B audits the proposed section output against that allow-list and flags anything that doesn't trace back to the original
- Layer C is an LLM-as-judge: a second Claude call independently classifies every bullet as verified, reformatted, ATS keyword, or fabricated — and if a section is judged fabricated, the API returns a 422 and the output is blocked entirely, never shown to the user
The tailoring prompt itself is over 20 rules long. It prohibits inventing companies, titles, dates, metrics, tools, or scope claims. It requires the model to populate a bulletEvidence field citing the verbatim source span from the original resume that justifies each new bullet. The scoring rubric is fixed and deterministic — re-running the analysis on the same resume and JD produces the same three scores.
Score-Driven Tailoring
One design decision I'm proud of: the fit analysis doesn't just produce a score — it produces a tuning plan. Each resume section gets a weight (0–10) estimating how many points the overall score would move if that section were rewritten. The total weight across all sections is capped at 18, forcing the model to be ruthless about prioritizing the highest-leverage sections rather than spreading suggestions evenly.
When the user tailors a section and saves it, those points are claimed immediately — no waiting for a re-analyze call to recognize the improvement. Score history is tracked across every session so users can see their progress over time.
The Security Layer
Because the product sits at the intersection of AI and user-uploaded documents, security needed to be thoughtful rather than checkbox-driven.
A few of the choices that mattered:
- SSRF protection on JD URL fetching — every URL is resolved via DNS, and the resulting IP is validated against all private/loopback/link-local ranges (including octal and hex short-form variants) before any outbound request is made
- Prompt injection fencing — all user-supplied content is wrapped in XML tags in every LLM prompt, so pasted job descriptions or resume text can't be used to hijack the model's instructions
- Error scrubbing —
safeError()filters every error response to ensure API keys, upstream URLs, and stack traces never leak to the client - Per-user AI rate limiting — a sliding window sits on top of the global rate limiter so no single account can exhaust the AI budget
- Model whitelist — user preferences cannot override which AI model is called; that's resolved server-side only
Tech Stack
| Layer | Technology |
|---|---|
| Frontend | React + Vite (TypeScript) |
| Backend | Node.js + Express (TypeScript) |
| Database | PostgreSQL |
| Primary AI | Anthropic Claude (claude-sonnet-4-6) |
| Search / Research AI | Perplexity Sonar Pro |
| Auth | Google OAuth + JWT (HTTP-only cookies) |
| Export | docx library + PDFKit |
| Contact Research | Hunter.io + Apollo + TheOrg |
| Deployment | Docker-compose ready, cloud-agnostic |
System Architecture
flowchart TD
A([User Uploads Resume]) --> B[Parse to Structured ResumeDoc\nAnthropic Claude]
B --> C[(Store Profile + Sections\nPostgreSQL)]
D([Create Job Session]) --> E{JD Input Method}
E -->|URL provided| F[Fetch JD via SSRF-safe Request\nDNS validation + IP blocklist]
E -->|Pasted text| G[Use Pasted JD Text]
F --> H[Extracted Job Description]
G --> H
H --> I[Analyze Fit\nAnthropic Claude]
I --> J[ATS Score + Alignment Score\nOverall Score and Verdict]
J --> K[Tuning Plan\nSection weights, total capped at 18]
K --> L[Workshop: Select Section to Tailor]
L --> M[Build Allow-List from Source ResumeDoc\nLayer A: proper nouns, numerics, skills, JD terms]
M --> N[Generate Tailored Section\nAnthropic Claude]
N --> O[Audit Output Against Allow-List\nLayer B: flag ungrounded tokens]
O --> P[LLM-as-Judge: Classify Each Bullet\nLayer C: verified / reformatted / ats_keyword / fabricated]
P --> Q{Fabrication Detected?}
Q -->|Yes| R[Block Output\nReturn HTTP 422]
Q -->|No| S[Return Word-level Diff to User]
S --> T{User Decision}
T -->|Approve| U[Save to TailoredDoc\nClaim score points]
T -->|Re-roll| N
T -->|Restore prior version| V[Load from Section History\nUp to 12 entries per section]
U --> W[Generate Cover Letter\nAnthropic Claude + Layer B audit]
W --> X[Research Contacts Pipeline]
X --> X1[Stage 1: Hunter.io\nNames and verified emails]
X1 --> X2[Stage 2: Apollo.io\nLinkedIn URL enrichment]
X2 --> X3[Stage 3: Perplexity Sonar Pro\nGap-fill via live web search]
X3 --> X4{Any results found?}
X4 -->|No| X5[Stage 4: TheOrg\nOrg chart fallback]
X4 -->|Yes| X6[Merge and Score Contacts\nDeduplicate by name, rank by type and confidence]
X5 --> X6
X6 --> X7[Attach why and outreach fields\nper contact]
X7 --> Y[Export Resume]
Y --> Z{Format}
Z -->|DOCX| Z1[Generate via docx library]
Z -->|PDF| Z2[Generate via PDFKit\nText-native, ATS-parseable]
Z1 --> AA[Apply via Original Job URL\nUpdate Application Status]
Z2 --> AA
style R fill:#3b1111,stroke:#7f1d1d,color:#fca5a5
style Q fill:#1a2035,stroke:#2563eb,color:#93c5fd
style P fill:#1a2035,stroke:#2563eb,color:#93c5fdThe diagram maps the full request lifecycle — from resume upload through tailoring, groundedness checks, contact research, and final export.
What's Next
Contact research runs as a four-stage waterfall: Hunter.io surfaces names and emails, Apollo enriches them with LinkedIn profiles, Perplexity fills gaps via live web search, and TheOrg serves as a last-resort fallback using org chart data.
The browser extension is also in progress. The idea is simple: you're on a job listing page, one click triggers the full analysis and pre-populates the session without leaving the tab.
The hardest thing to get right — and the thing I keep coming back to — is keeping the AI honest. The temptation when building a tool like this is to optimize for outputs that look impressive. TailorSwan is deliberately built to optimize for outputs that are accurate. The best version of this product is one that helps people get jobs they're genuinely qualified for, faster — not one that helps anyone bluff their way into a room they shouldn't be in.
TailorSwan is live at tailorswan.me.
